LOF - Local Outlier Factor 局部异常因子算法
LOF 是无监督、基于密度的异常检测算法,核心思想:异常点的局部密度显著低于周边邻居,通过量化「局部密度差异」给出每个样本的异常分数。
LOF 的适用场景:
- 数据集存在多个疏密不同的聚类
- 不需要异常标签,纯无监督筛查离群点
核心公式
当前距离公式采用欧式距离。
1. $k\text{-distance}(p)$ 第 $k$ 邻近距离
$$k\text{-distance}(p) = d(p,o_k)$$其中,$o_k$ 是距离样本 $p$ 第 $k$ 近的样本。邻域 $N_k(p)$ 是所有距离样本 $p$ 小于等于 $k\text{-distance}(p)$ 的样本的集合,如下图:
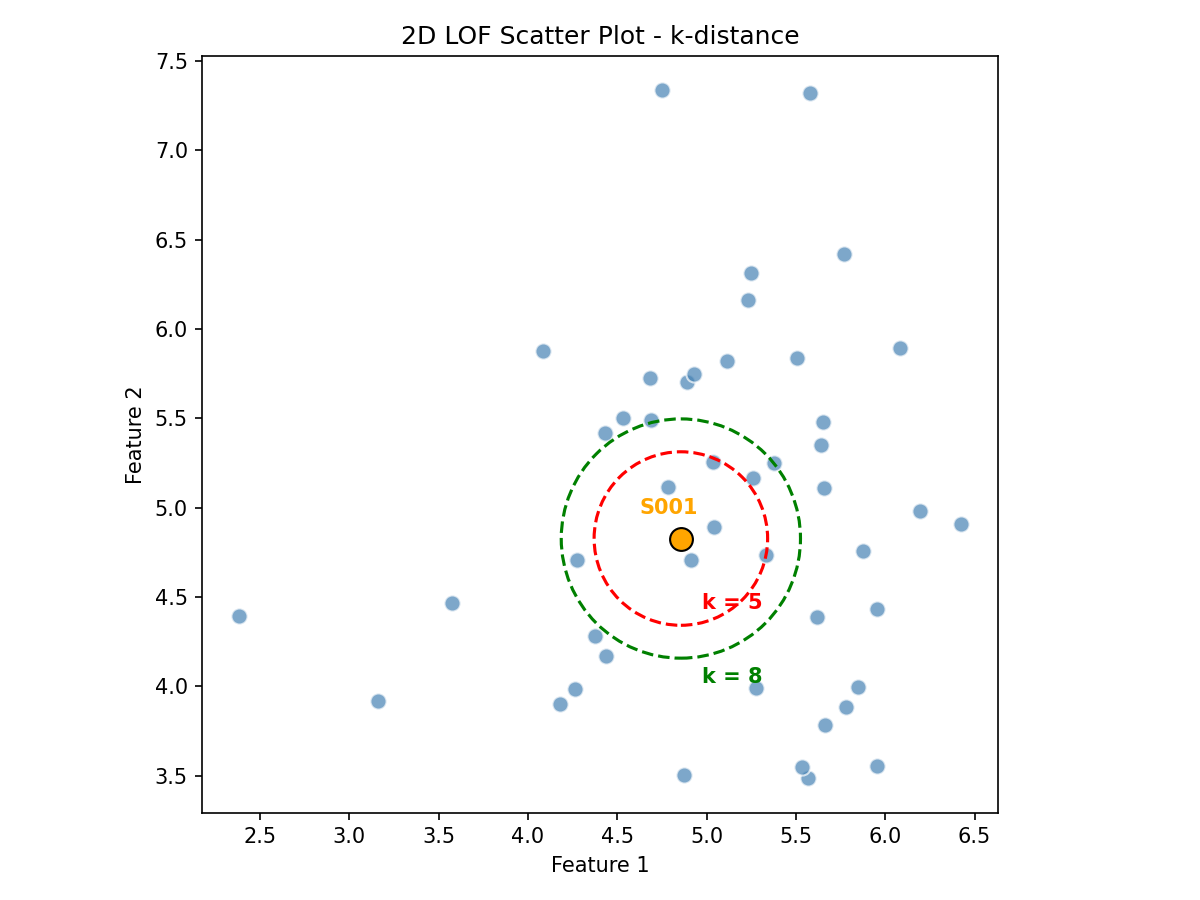
- 当 $k$ 为 5 时,记 $N_5(S001)$,邻域样本个数为 5
- 当 $k$ 为 8 时,记 $N_8(S001)$,邻域样本个数为 8
邻域样本个数可以大于 $k$,即可能存在多个距离等于 $k\text{-distance}(p)$ 的样本。
2. $\operatorname{reach-disk}_k(p,o)$ 可达距离
可达距离公式如下:
$$\operatorname{reach-disk}_k(p,o) = \max\big(k\text{-distance}(o),\ d(p,o)\big)$$对于样本 $p$ 到样本 $o$ 的可达距离表示:
- 当样本 $p$ 在邻域 $N_k(o)$ 内时,可达距离为 $k\text{-distance}(o)$
- 当样本 $p$ 在邻域 $N_k(o)$ 外时,可达距离为 $d(p,o)$
如下图:
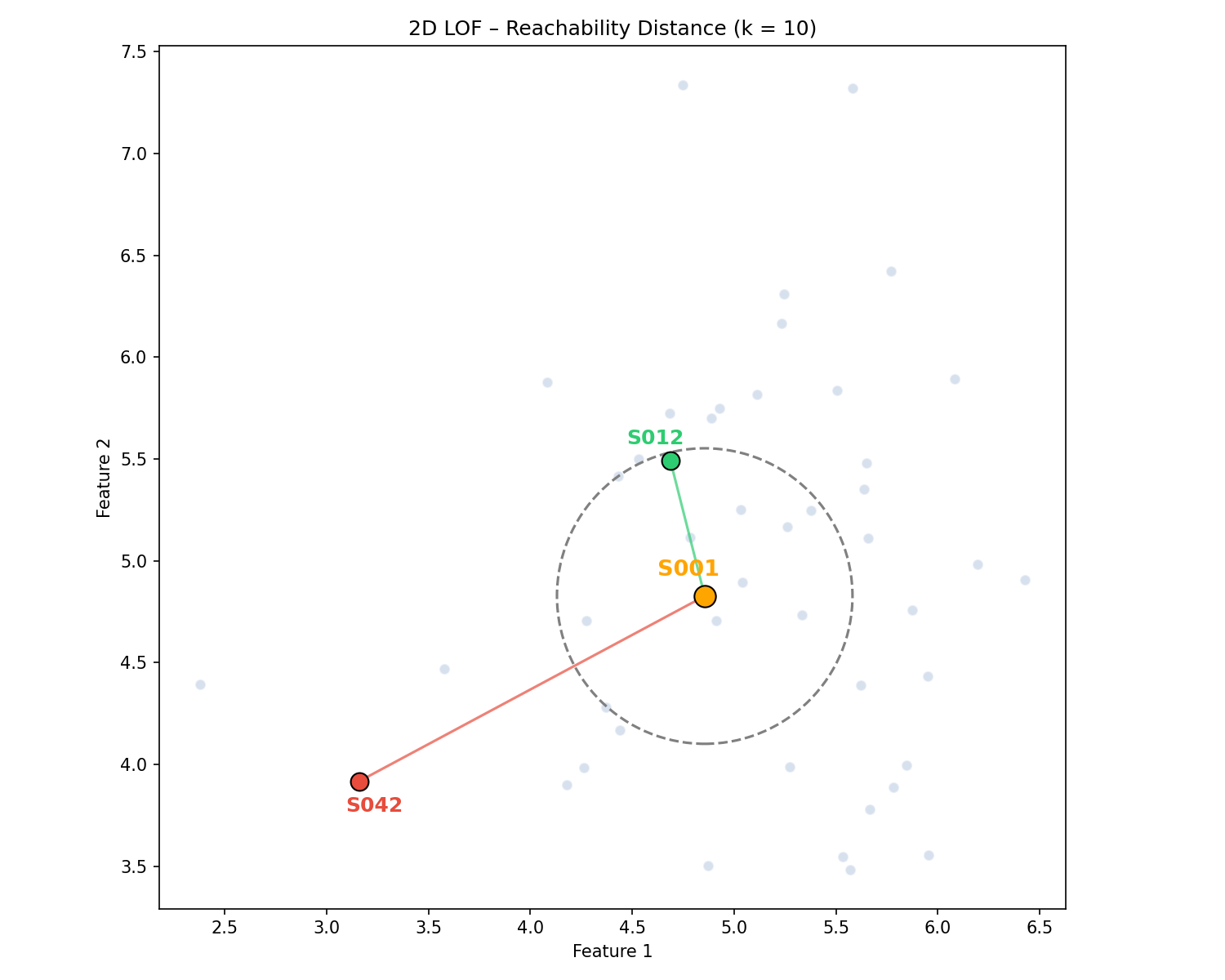
- 样本 S012 在样本 S001 的邻域 $N_{10}(S001)$ 内
- 样本 S042 不在样本 S001 的邻域 $N_{10}(S001)$ 内
- 样本 S012 到样本 S001 的可达距离为 $k\text{-distance}(S001)$
- 样本 S042 到样本 S001 的可达距离为 $d(S042,S001)$
可达距离的作用:同一簇内距离很近的样本统一用邻居的 k-distance 抹平,避免微小距离波动干扰密度计算。
3. $\operatorname{LRD}_k(p)$ 局部可达密度
$\operatorname{LRD}_k(p)$ 局部可达密度用于衡量样本 $p$ 所在局部区域的样本密集程度,其公式如下:
$$\operatorname{LRD}_k(p) = \frac{1}{\displaystyle \frac{1}{\left|N_k(p)\right|}\sum_{o\in N_k(p)} \operatorname{reach-disk}_k(p,o)} = \frac{\left|N_k(p)\right|}{\sum_{o\in N_k(p)} \operatorname{reach-disk}_k(p,o)}$$表示样本 $p$ 邻域平均可达距离的倒数,$\operatorname{LRD}_k(p)$ 越大,则 样本 $p$ 周围的样本越密集,反之则越稀疏。
如下图:
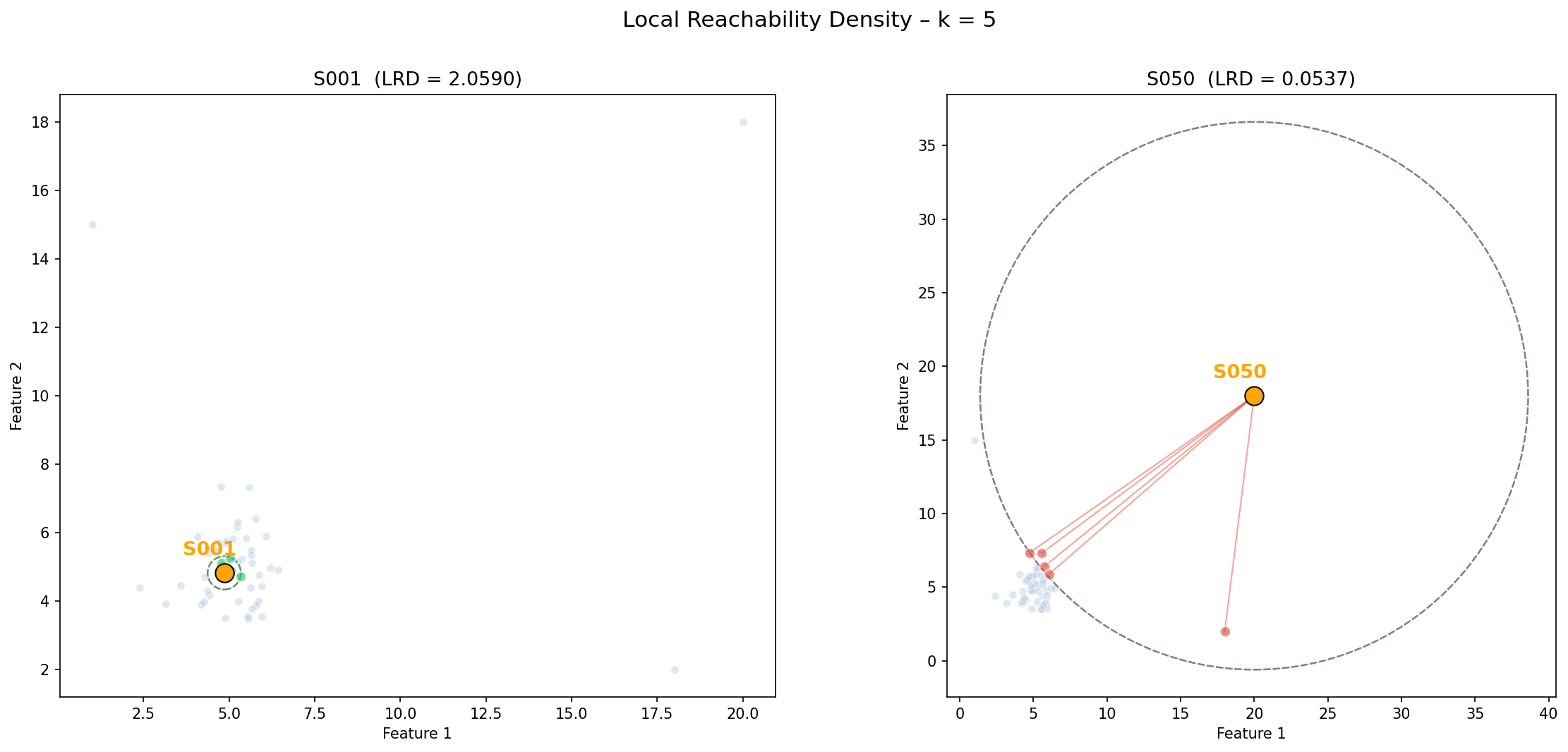
$LRD_{5}(S001)$ 为 2.0590,而 $LRD_{5}(S050)$ 为 0.0537,显然样本 S050 周围的样本更稀疏。
4. $\operatorname{LOF}_k(p)$ 局部异常因子
$\operatorname{LOF}_k(p)$ 局部异常因子公式如下:
$$\operatorname{LOF}_k(p) = \frac{\displaystyle \frac{1}{\left|N_k(p)\right|}\sum_{o\in N_k(p)} \operatorname{LRD}_k(o)}{\operatorname{LRD}_k(p)}$$其表示样本 $p$ 的邻居平均局部可达密度除以当前样本的局部可达密度:
- 当 $\operatorname{LOF}_k(p) \approx 1$ 时,样本 $p$ 密度约等于邻居密度,样本 $p$ 为正常样本
- 当 $\operatorname{LOF}_k(p) \gg 1$ 时,样本 $p$ 密度远低于邻居密度,样本 $p$ 为异常样本
- 当 $\operatorname{LOF}_k(p) < 1$ 时,样本 $p$ 比邻居更密集
如下图:
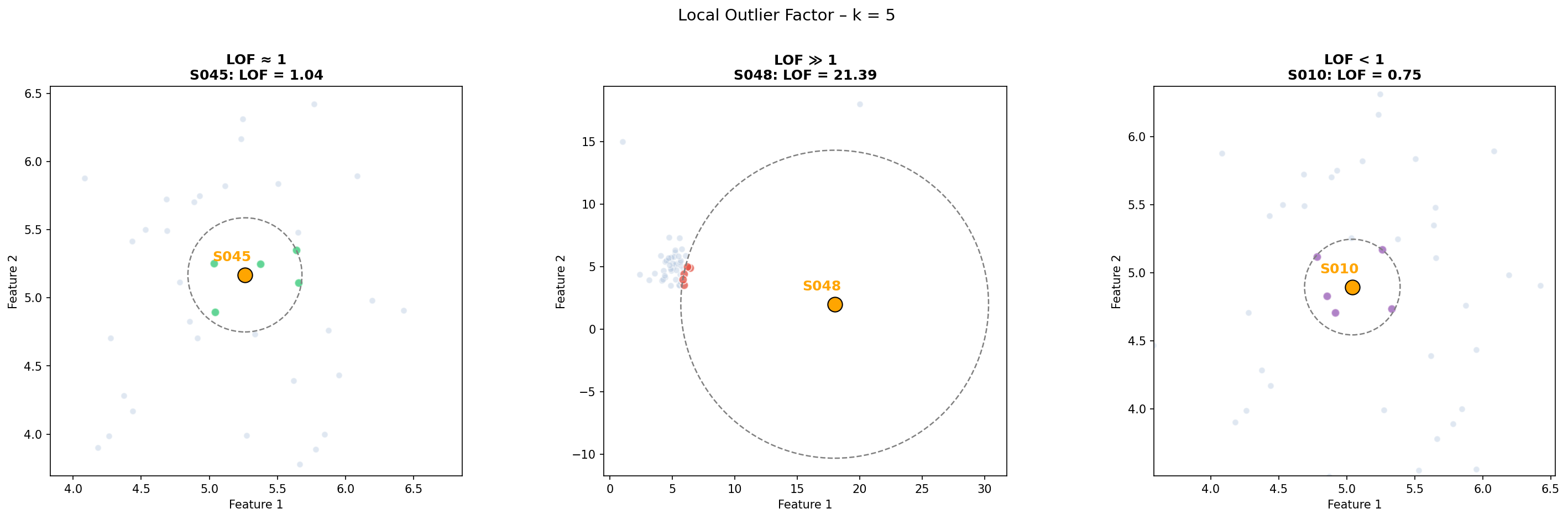
计算过程
LOF 局部异常因子算法需要计算所有样本的 LOF 值,完整的计算过程如下:
- 遍历全部样本,计算每个点两两距离,得到每个点的 $k$ 近邻集合 $N_k(p)$
- 对每一个样本,计算 $k\text{-distance}(p)$
- 遍历所有样本 $p$,再遍历它的每一个邻居 $o\in N_k(p)$,计算 $\operatorname{reach-disk}_k(p,o)$
- 逐个算出全部样本的 $\operatorname{LRD}_k(p)$
- 再逐个算出全部样本的 $\operatorname{LOF}_k(p)$
计算出所有样本的 $\operatorname{LOF}_k(p)$ 值,如何确定异常样本?常规作法是将 LOF 最高的 5% 的样本定义为异常样本,当然也可以结合领域知识设置阈值,将大于阈值的样本定义为异常样本。
如下图:
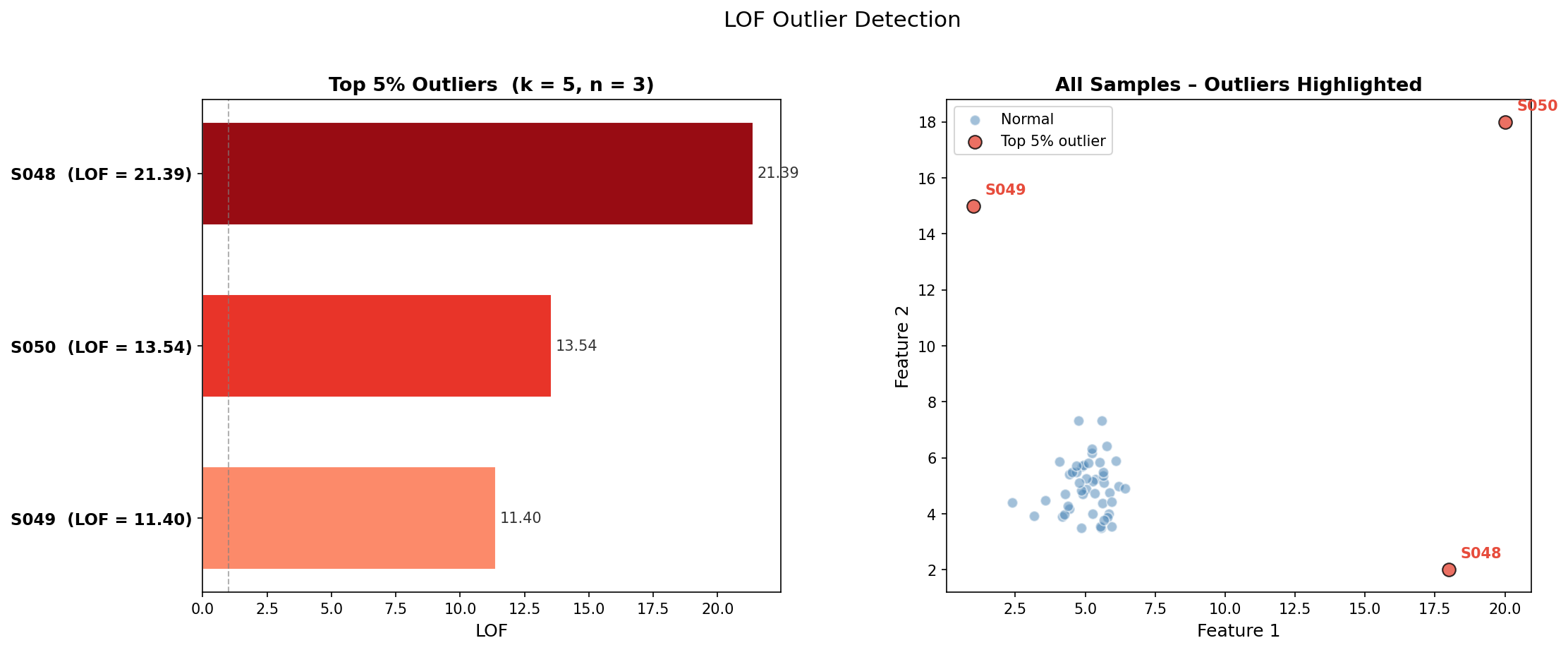
异常样本为 S048、S050、S049,结合散点图,也验证了 LOF 局部异常因子算法的结果是准确的。
确定 $k$ 值
描述一种确定 $k$ 值的方法,即 k-distance 肘部法则,其思路是绘制每一个样本的“k ~ k-distance”曲线,整体曲线明显拐弯处的 $k$ 值即为最优 $k$ 值。步骤如下:
- 定义候选 $k$ 值集合
- 遍历 $k$ 值集合
- 计算每个样本的 k-distance
- 计算平均 k-distance,绘制图表(柱状图+折线图)
- 计算单段斜率变化率,即二阶差分
如下图:
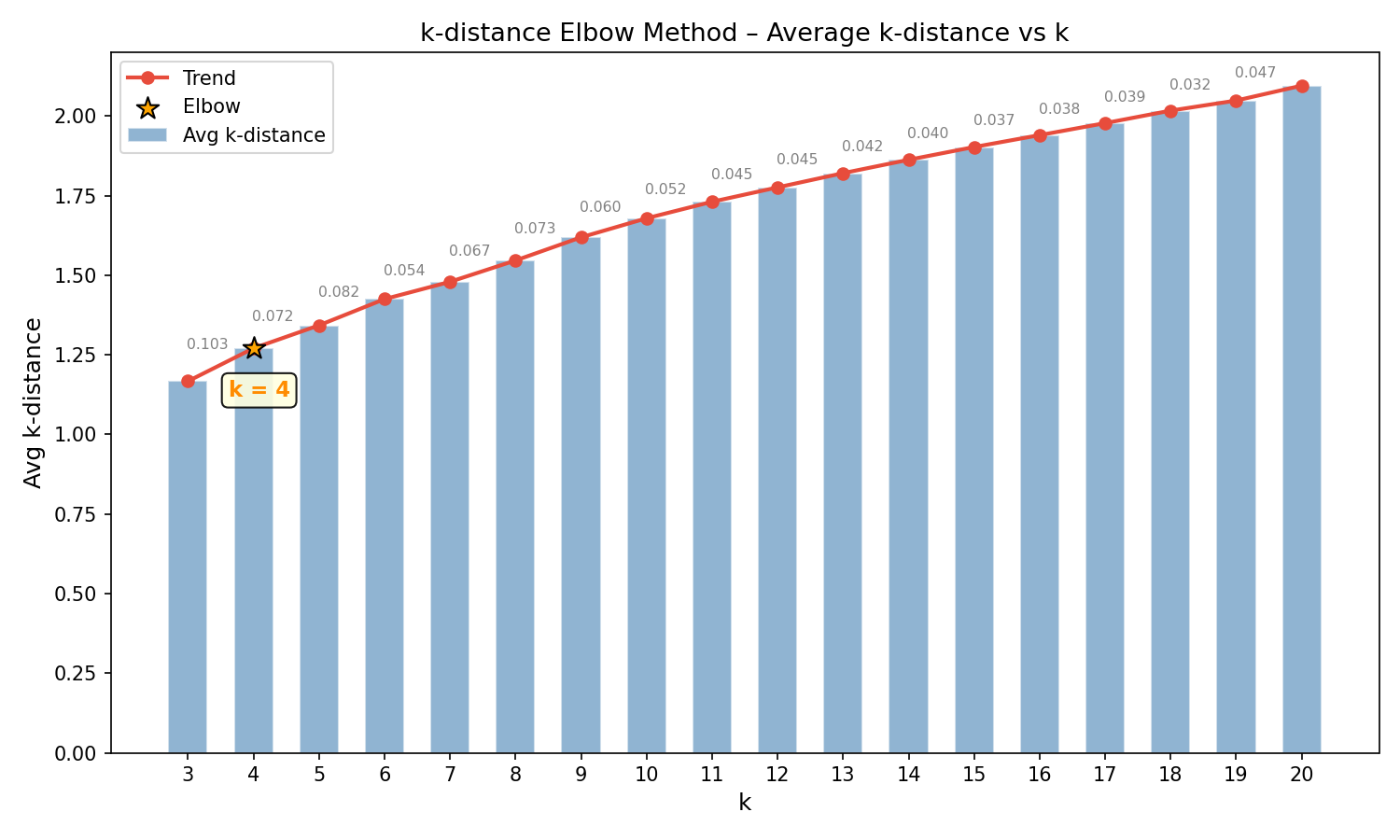
- 灰色数值表示单段拆线的斜率
- 当 $k$ 值从 4 到 5 时,斜率的变化最大
所以,示例数据集的 LOF 局部异常因子算法的最优 $k$ 值为 4。